This article was originally published on Substack.
There’s a comforting certainty in metrics. When we look at a confusion matrix or an accuracy score, we feel like we understand how reliable our AI model will be. And if that number is high, say 95% we may assume it’s safe for us to use.
But accuracy is a measure of the past. It tells us how well the model learned the patterns in the data. Even if we’ve tested it on data we set aside and it looks good, it can still carry risk when deployed.
Especially when it runs automatically.
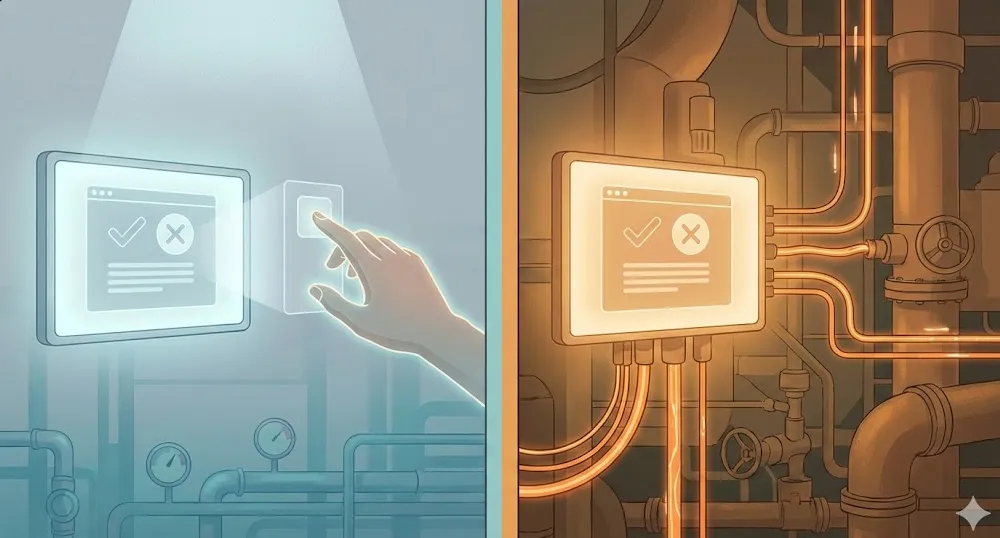
And that points to a question we rarely ask: Is this system allowed to act, or only to suggest?
Because metrics don’t define risk. Authority does.
Same model. Very different consequences.
Imagine a model trained to identify shale intervals from well logs. This may seem like a basic task better handled by traditional petrophysical equations, but I’ve seen several models over the years trained to predict shale volumes. For this example, it illustrates the point nicely: something basic, yet crucial for downstream modelling.
The model has been trained on historical data. It performs well on validation. Most outputs look reasonable to an experienced petrophysicist. The kind of model that passes every review gate you throw at it.
Now consider two ways it gets used.
In the first, the model highlights likely shale intervals for review. An interpreter sanity-checks them, adjusts where needed, and moves on. If something looks off, they fix it. If it misses an interval, they catch it. The model is doing what it’s designed to do. It surfaces information for a human to evaluate.
In the second, the same model automatically flags shale and feeds directly into net pay and volumetric calculations downstream. No review step. No sanity check. The outputs go straight into the numbers that inform decisions about where to drill and how much resource is in the ground.
Same model. Same accuracy. Completely different risk profile.
In the first case, errors are cheap and visible. Someone sees them, corrects them, and gets on with their day. In the second, small mistakes quietly propagate into calculations that few people revisit. A slightly wrong shale flag here, a net pay estimate that’s quietly optimistic there. None of it dramatic enough to raise an alarm, but all of it accumulating in a direction nobody intended.
Nothing about the model changed. Only its freedom to act did.
Accuracy doesn’t capture authority
This is the blind spot.
We often treat accuracy as a proxy for safety. If the model scores well on test data, we assume it’s safe to deploy. But accuracy tells you how often a model matched historical labels. That’s it. It says nothing about what happens when it doesn’t match, and more importantly, it says nothing about how much influence the model has when it gets things wrong!
That’s where autonomy comes in.
A fairly average model that only suggests can be perfectly acceptable. The outputs are there for someone to look at, evaluate, and override. The human retains control, and the cost of a wrong prediction is low. It’s just a suggestion that gets ignored.
A very good model that executes automatically is a different story. Even if it’s right 95% of the time, that remaining 5% now has real-world consequences. And the problem gets worse when conditions drift away from the training data, which, in any kind of subsurface work, they inevitably do. Wells aren’t drilled in the same geology forever. Formations vary. Tools change. Logging environments shift.
Yet, we spend most of our time debating model performance and almost none discussing what the model is allowed to do with its predictions.
How autonomy sneaks in
Very few teams sit down and say: “Let’s give this model decision-making authority.”
What usually happens is more subtle. And honestly, more human.
A suggestion becomes the default. Nobody overrides it because it’s usually right. The default becomes “just run it” because there’s pressure to move faster. Someone adds a checkbox: Apply automatically. It saves 20 minutes per well. Nobody objects.
Nothing about the maths changed. But the system’s behaviour did.
I’ve seen this pattern play out more times than I can count, not because anyone made a bad decision, but because each individual step made perfect sense. The model was good. The suggestion was usually right. The override was rarely needed. So why not streamline it?
The answer is that at some point, the model stopped analysing data and started shaping outcomes. Often several steps removed from where it was trained or evaluated. And that transition happened without anyone formally deciding it should.
”But we have a human in the loop”
This is where people often feel reassured. And I understand why. It sounds like a safety net.
But, in practice, “human-in-the-loop” can mean very different things. It can mean a petrophysicist carefully reviewing each output against independent data, with the time and context to form their own judgment. That’s real oversight.
Or it can mean reviewing dozens of outputs at once, with limited context, under time pressure, where the model usually looks sensible and the path of least resistance is to agree.
If the model is right 95% of the time, the human learns to trust it. Override rates drop. Review becomes faster. And at some point, the human isn’t really making decisions anymore. They are confirming them.
Which raises an uncomfortable question: who is actually making the decision?
I’ll come back to that in a later piece, because human-in-the-loop degradation deserves its own discussion. But for now, the point is this: the presence of a human doesn’t automatically mean oversight is happening. It depends on what that human is actually doing, and whether the system is designed to support genuine review or just to provide the appearance of it.
Why this matters in subsurface work
In subsurface interpretation workflows, failures are rarely obvious. There’s no alarm bell. No red warning on a screen. Most of the time, things don’t visibly break, they quietly drift and may go unnoticed for some time.
A shale flag that’s slightly off here. A net pay estimate that’s quietly optimistic there. A porosity cutoff that’s been applied automatically for six months without anyone questioning it.
By the time someone spots the issue, maybe during a reserves audit, maybe when a well underperforms, the model is long out of sight. But its influence isn’t. It’s embedded in the volumetrics, in the reservoir model, in the development plan. And unpicking it means going back through dozens of wells to figure out where the model’s outputs ended and human judgment began.
That’s the real cost. Not a single wrong answer, but the accumulated weight of decisions that were never really made by the people who were supposed to be making them.
That’s why autonomy deserves as much attention as model choice. Possibly more.
A better design question
Before asking “how accurate is this model?”, I think there are more useful questions to start with.
What is this system allowed to change? Where in the workflow do its outputs go, and how far downstream do they travel before someone looks at them again? What still requires explicit approval. Not just in theory, but in the day-to-day reality of how people actually use the tool?
Where do errors surface first? Is there a mechanism for catching mistakes, or does the workflow assume the model is right until proven otherwise? And when an error does surface, who notices it. And do they have the context and authority to do something about it?
Those answers define the real risk. Not the accuracy metric on a test set, but the practical question of what happens when the model is wrong and nobody catches it.
Final thought
AI doesn’t become risky because it’s wrong. Every model is wrong sometimes. That’s expected, and in a well-designed workflow, it’s manageable.
It becomes risky when we give it authority without friction. When suggestions become defaults, defaults become automation, and the human oversight that was supposed to catch problems quietly fades into a formality.
And that decision, the one about how much freedom to give the system, is almost never captured in a metric.
It probably should be.